Hay un momento en la vida de casi todo sistema que envejece en el que alguien de la empresa dice, con convicción y cansancio acumulado: "hay que reescribirlo todo".
Es comprensible. El código legacy duele. Los deploys tardan horas. Nadie entiende por qué esa función hace lo que hace. Los tests no existen o mienten. Cada feature nueva es una cirugía con anestesia local. La deuda técnica acumulada hace que hasta los cambios simples sean riesgosos.
El problema es que reescribir un sistema desde cero — lo que se conoce como big bang rewrite — tiene una tasa de fracaso altísima. Y no por falta de talento técnico, sino por razones estructurales que se repiten en casi todos los proyectos.
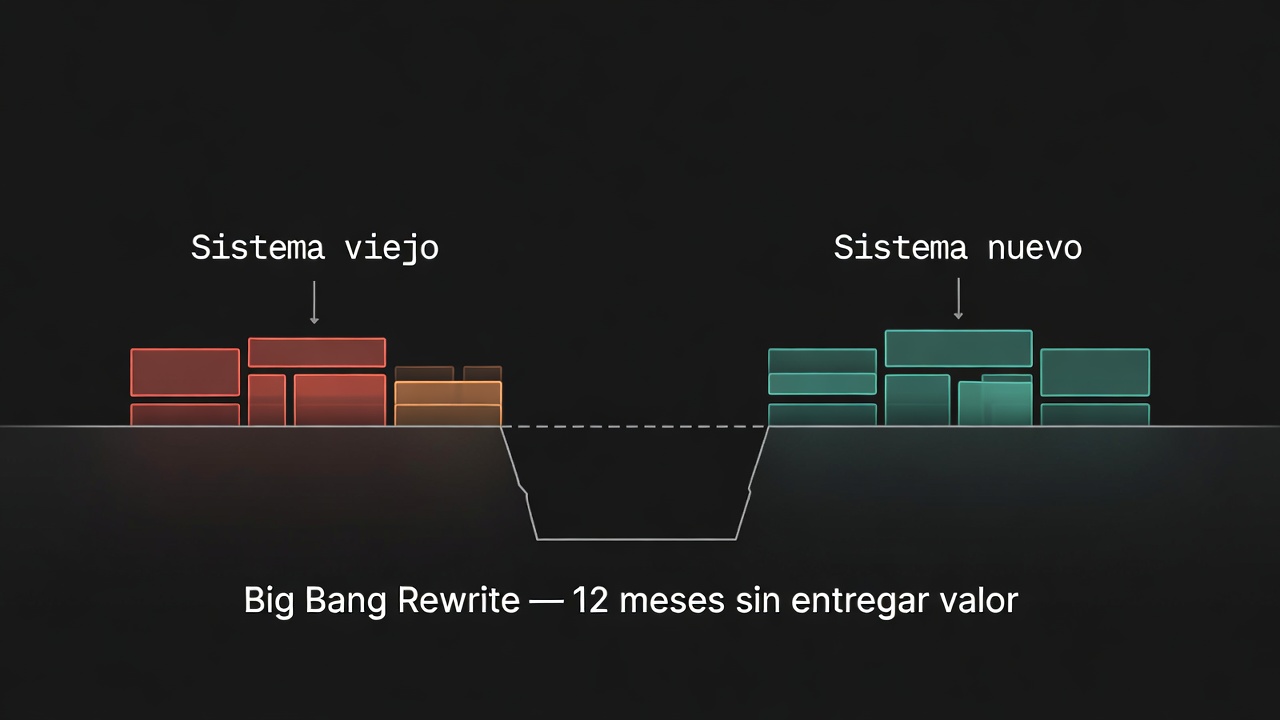
Por qué falla el big bang rewrite
1. El sistema viejo sabe cosas que nadie documentó
Ese código que parece sin sentido generalmente tiene sentido. Hay lógica de negocio enterrada en condiciones raras, edge cases que nadie recuerda pero que un cliente en algún lugar del mundo ejecuta todos los meses, integraciones con sistemas externos que tienen comportamientos no documentados.
Cuando reescribís desde cero, perdés ese conocimiento. No lo recuperás del código, porque era ilegible. No lo recuperás de la documentación, porque no existe. Lo descubrís cuando el sistema nuevo falla en producción de formas misteriosas, semanas después del go-live.
2. El target se mueve mientras construís
Un rewrite grande lleva meses. En ese tiempo, el negocio no para. Se agregan features al sistema viejo. Se cambian reglas. Se incorporan nuevos clientes con nuevos requisitos.
Cuando terminás el rewrite, el sistema nuevo ya está desactualizado respecto al viejo. Y el viejo siguió creciendo sin que nadie lo modernizara con criterio.
Mes 1-3: [Sistema viejo funciona] ← equipo trabajando en él
Mes 4-9: [Sistema viejo funciona] + [Rewrite en paralelo]
Mes 10-12: [Sistema viejo cambió] ≠ [Rewrite basado en versión de mes 3]
Resultado: el rewrite llega tarde y desactualizado
3. La deuda técnica se regenera
Sin los procesos, la cultura y las prácticas que evitan la deuda técnica, el sistema nuevo va a terminar en el mismo estado que el viejo. Solo que más rápido, porque ahora todos están apurados por recuperar el tiempo perdido en el rewrite.
La deuda técnica no es un problema de código. Es un problema de prácticas de equipo. Reescribir el código sin cambiar las prácticas es cambiar de casa sin cambiar los hábitos.
Qué hacer en cambio: migración incremental de sistemas legacy
La alternativa es la migración incremental. En lugar de reescribir todo, identificás las partes más críticas o más dolorosas y las modernizás de a una, sin bajar el sistema.
El principio central: no mantenés dos sistemas completos como fuente de verdad en paralelo. Siempre hay uno que manda, y el otro va creciendo por piezas hasta poder reemplazarlo.
Strangler Fig Pattern
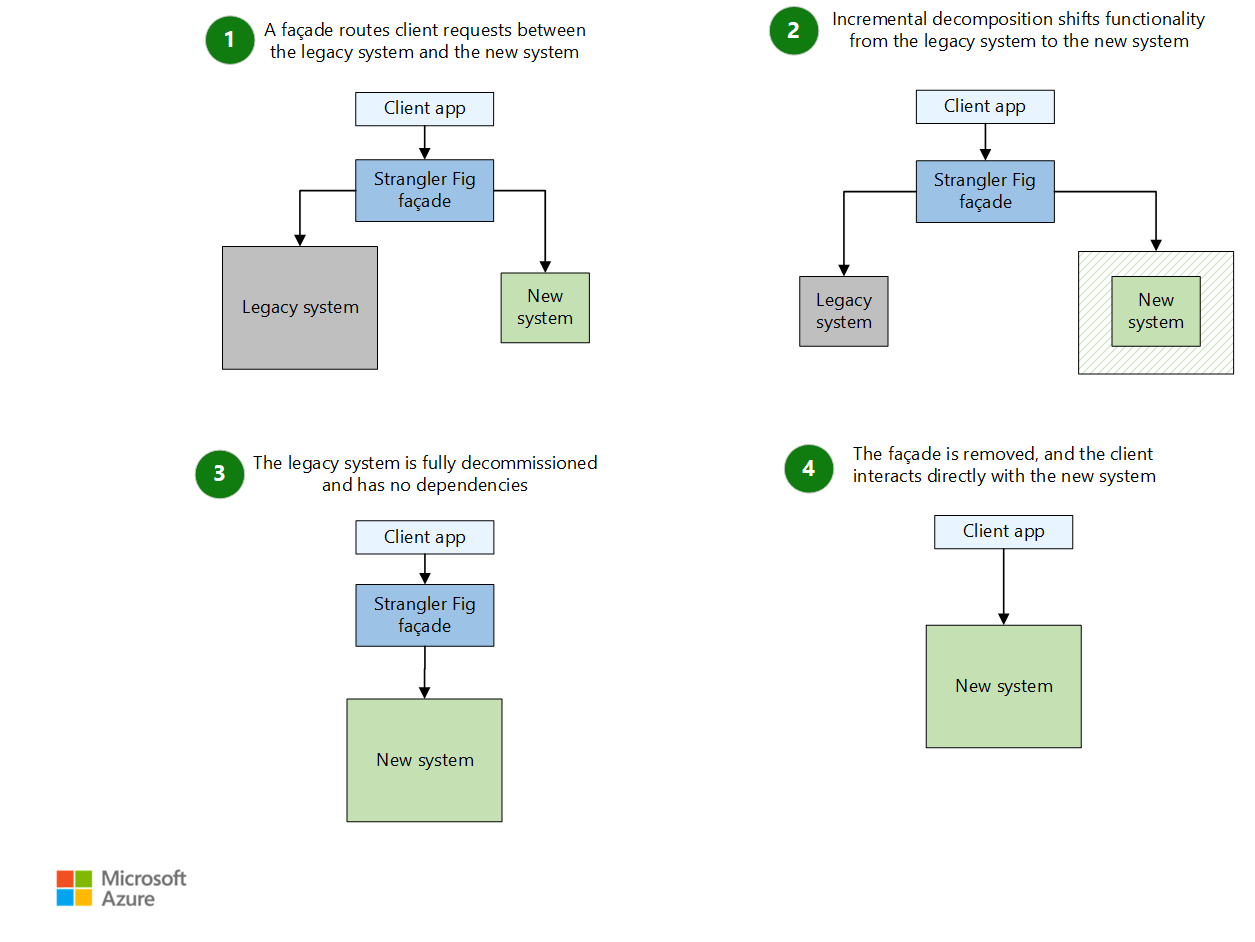
El flujo práctico:
- Ponés un proxy o router delante del sistema viejo
- Las nuevas funcionalidades van directamente al sistema nuevo
- Las funcionalidades existentes se migran de a una al sistema nuevo
- A medida que el sistema nuevo crece, el proxy redirige más tráfico hacia él
- Con el tiempo, el sistema viejo queda sin funcionalidad y lo apagás
La ventaja crítica: nunca dejás de entregar valor. El sistema viejo sigue funcionando mientras construís el nuevo alrededor de él.
En la práctica, este patrón funciona mejor cuando definís fronteras claras por capacidad de negocio (por ejemplo: autenticación, facturación, reporting) y migrás una por vez con métricas de éxito explícitas.
Si hoy no sabés por dónde empezar, una auditoría técnica acotada te ayuda a priorizar módulos y secuencia de migración antes de invertir meses en dirección equivocada.
Feature flags
Activás el código nuevo solo para un porcentaje del tráfico. Validás en producción real antes de hacer el corte completo. Si algo falla, desactivás el flag y volvés al comportamiento anterior en segundos, sin deploy.
Es especialmente útil para migrar módulos críticos como autenticación, pagos o cálculos de negocio complejos, donde el riesgo de error es alto.
Anti-corruption layer
Una capa que traduce entre el modelo del sistema viejo y el nuevo, permitiendo que convivan sin que uno contamine al otro. Cuando el módulo de pagos nuevo necesita datos del módulo de usuarios viejo, el anti-corruption layer hace la traducción de modelos.
Cómo ejecutar una migración incremental sin improvisar
Si querés que la estrategia funcione en producción, definí estas reglas desde el día 1:
- Un ownership técnico claro por dominio. Cada módulo migrado tiene responsable.
- Métricas mínimas por etapa. Error rate, latencia y tiempos de rollback.
- Criterio de "done" por módulo. Qué tiene que pasar para apagar la parte legacy.
- Plan de reversión probado. No alcanza con “debería volver”; hay que ensayarlo.
- Límites de WIP. Mejor dos migraciones terminadas que seis empezadas.
Big bang rewrite vs. migración incremental
| Factor | Big bang rewrite | Migración incremental |
|---|---|---|
| Tiempo hasta primer valor | 6-18 meses | 2-4 semanas |
| Riesgo de perder lógica de negocio | Alto | Bajo |
| Capacidad de responder a cambios | Nula durante el rewrite | Continua |
| Costo de un error crítico | Catastrófico (rehacer meses) | Acotado (revertir un módulo) |
| Necesita bajar el sistema | Sí (cutover) | No |
| Probabilidad de éxito | Baja (~30%) | Alta (~75-80%) |
Cuándo sí tiene sentido reescribir desde cero
Hay casos donde el rewrite es legítimo. Son excepciones, no la regla:
- El sistema tiene tan poco tráfico que podés hacer el corte en un fin de semana sin impacto real
- La tecnología es tan obsoleta que no hay forma de ejecutarla en infraestructura moderna (ej: sistemas en COBOL sin runtime disponible)
- El scope del rewrite es muy acotado — un módulo aislado, no el sistema completo
- El sistema tiene menos de 6 meses de vida y la deuda técnica es de diseño, no de años de acumulación
Si tu caso no entra en ninguno de estos, la migración incremental es casi siempre la respuesta correcta.
Preguntas frecuentes sobre modernización de sistemas legacy
¿Cuánto tarda una migración incremental?
Depende del tamaño del sistema y del alcance, pero el primer valor suele llegar en semanas, no en semestres. Esa diferencia es clave para reducir riesgo y sostener apoyo del negocio.
¿Se puede hacer sin frenar el roadmap de producto?
Sí, si definís un plan por dominios y límites de trabajo en paralelo. El objetivo es modernizar sin apagar delivery.
¿Qué módulo conviene migrar primero?
Normalmente, el que combina mayor dolor operativo y menor dependencia transversal. Empezar por una victoria controlada mejora aprendizaje y baja riesgo para lo siguiente.
La próxima vez que alguien proponga el big bang rewrite, la pregunta correcta no es "¿con qué tecnología lo reescribimos?". Es: ¿qué parte específica nos está doliendo más y cómo la modernizamos sin tirar todo?
Es menos épico. Es más efectivo. Y es lo que realmente funciona en producción.
Referencia
El enfoque de Strangler Fig de este artículo está basado en el patrón documentado por Microsoft Learn: Strangler Fig pattern (Azure Architecture Center).
¿Tenés un sistema legacy que necesita modernización y no sabés por dónde empezar? En Madariaga SAS hacemos diagnósticos técnicos que identifican exactamente qué modernizar, en qué orden, y con qué estrategia. Ver cómo funciona la auditoría técnica →